Swift “Copy-On-Write”
Swift 공식 홈페이지에 들어가면 Swift를 아래와 같이 소개하고 있습니다.

여기서 이번 주제에 대한 내용은 “Swift 코드는 안전하게 설계되었으며” 와 관련이 있습니다.
좀 더 아래로 내려가보면 아래와 같이 설명하고 있습니다.
안전 중심 설계
Swift는 불안전한 코드의 전체 클래스를 제거합니다. 변수는 사용 전에 항상 초기화되고, 배열 및 정수에 대한 오버플로우 검사가 수행되며, 메모리는 자동으로 관리됩니다. 또한 메모리에 대한 독점적인 접근을 통해 많은 프로그래밍 실수가 발생하지 않도록 보호합니다. 개발자의 의도를 쉽게 정의할 수 있도록 구문이 조정됩니다. 예를 들어 세자로 된 간단한 키워드를 사용하여 변수(var) 또는 상수(let)를 정의합니다. 뿐만 아니라 Swift는 특히 배열 및 딕셔너리와 같이 일반적으로 사용되는 값 타입을 최대한 활용합니다. 이는 해당 타입으로 사본을 만들 경우 다른 곳에서 수정할 수 없다는 것을 의미합니다.
Swift는 일반적으로 값 타입을 최대한 활용한다고 합니다.
여기서 값타입은 무엇이고 다른 타입은 무엇이 있는지 알아보겠습니다.
- 값 타입 (Value Type)
- 값 타입은 struct, enum, tuple등에 사용되며, 다른 변수에 할당 시, 완벽하게 copy됩니다.
- 이는, 각각의 변수에 할당된 data는 서로 공유되지 않으며 각각에 unique 하다는 말이 됩니다.
- 각각 자신만의 고유한 data를 처리하기 때문에, 다중 스레드 환경에서도 data의 안정성이 보장됩니다.
- 그러나 할당 시 마다 고유한 copy본을 생성하기 때문에, copy에 대한 비용과 시간이 들게 됩니다.
- 참조 타입 (Reference Type)
- 참조 타입은 class instance를 사용하는 것과 동일합니다.
- class instance는 다른 변수에 할당할 경우, copy되는 것이 아닌 instance의 주소를 참조하게 됩니다.
- 하나의 class instance를 여러 변수에서 공유하기 때문에, 다중 스레드 환경에서 data의 유효성 및 안정성이 보장되지 않습니다. (동시에 여러 곳에서 값을 변경하려고 할때, 어떤 값이 먼저 적용될지, 아니면 아예 적용자체가 무시될지 보장되지 않습니다.)
- 그러나 하나의 instance를 참조하여 사용하므로, 별도의 copy 비용이 없습니다.
무슨 마법을 부렸길래, 값 타입임에도 불구하고 빛의 속도로 빠른걸까요??
지금부터 다루어볼 Copy-On-Write라는 방식이 바로 마법도구입니다.
Copy-On-Write? 그게 뭔데?
Copy-On-Write(COW)는 값 타입에서 발생하는 복사 비용을 줄이기 위해 사용되는 기법입니다.
값 타입의 경우, 새로운 인스턴스가 생성될 때마다 모든 내용을 복사해야 합니다.
이 때, 값 타입의 크기가 크거나 복사가 빈번하게 일어나면 성능에 영향을 미칩니다.
COW를 사용하면, 값 타입을 복사할 때, 실제로는 데이터를 공유하다가 값이 변경될 때에만 복사를 수행합니다.
즉, 복사를 최소화하여 성능을 개선할 수 있습니다.
예를 들어, 배열을 복사할 때, 여러 변수가 동일한 데이터를 참조하고 있을 경우,
데이터를 공유하다가 하나의 변수에서 데이터가 변경되는 경우에만 새로운 데이터를 복사합니다.
이를 통해, 데이터 공유로 인한 복사 비용을 줄이면서도 값의 변경을 안전하게 보장할 수 있습니다.
COW는 Swift의 Array, Dictionary, Set 등에서 사용되고 있으며,
이를 통해 값 타입에서도 높은 성능을 보장할 수 있습니다.
import Foundation
func address(of object: UnsafeRawPointer) -> String {
let address = Int(bitPattern: object)
return String(NSString(format: "%p", address))
}
var arr = [1,2,3]
var arr2 = arr
print("최초 Array<Int>의 주소값 \(address(of: &arr))\n")
print("새로운 변수에 할당 후 arr 의 주소값 \(address(of: &arr))")
print("새로운 변수에 할당된 arr2의 주소값 \(address(of: &arr2))\n")
arr2.append(50)
print("arr2의 값을 변경한 후 원본과 변경된 arr의 값 비교\n\n원본 : \(arr)\n할당 : \(arr2)\n")
print("값 수정 후 원본 arr의 주소값 \(address(of: &arr))")
print("값 수정 후 복사본 arr2의 주소값 \(address(of: &arr2))")
Array
원래의 값 타입의 경우, 새로운 인스턴스가 생성될 떄 마다, Copy를 한다고 했으니, 당연히 두 변수의 주소값은 다르리라.. 바로 확인해보았습니다.

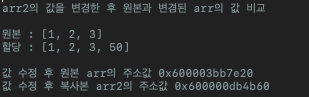
정말로 새로운 인스턴스에 값을 변경하니 그제서야 다른 주소값을 가지고 있습니다.
기법의 설명대로 Copy On Write를 하고있습니다.
결국 데이터를 여기저기 참조하여 읽어 들일때는 최초 생성된 값 타입을 공유하여 copy에 발생하는 비용을 사용하지 않기 때문에, 참조 타입과 동일하게 별도의 비용이 발생하지 않고, 실제로 값을 변경하게 되면, 그제서야 새로운 인스턴스를 생성하게 되므로, 다중 스레드 환경에서의 data 유효성에 대한 보장도 가능하게 되는것입니다.
아래는 copy on write를 custom한 값 type에 어떻게 적용해야 하는지 나타내주는 코드입니다.
final class Ref<T> {
var val : T
init(_ v : T) {val = v}
}
struct Box<T> {
var ref : Ref<T>
init(_ x : T) { ref = Ref(x) }
var value: T {
get { return ref.val }
set {
if (!isUniquelyReferencedNonObjC(&ref)) {
ref = Ref(newValue)
return
}
ref.val = newValue
}
}
}
// This code was an example taken from the swift repo doc file OptimizationTips
// Link: https://github.com/apple/swift/blob/master/docs/OptimizationTips.rst#advice-use-copy-on-write-semantics-for-large-values
- 값 타입을 최초로 생성하면 참조 카운트를 1로 설정합니다.
- 값 타입을 다른 변수에 할당하면 참조 카운트를 1개 증가시킵니다. (복사안함)
- 값 타입의 내부 변수를 다른 값으로 write 하려고 하면 다음의 동작이 수행됩니다.
- 이때 사용되어지는게 isUniquelyReferencedNonObjC() 메소드 입니다.
- 현재 내가 가진 참조 카운트가 1인지(unique한지) 확인하여 1이라면 내가 가진 변수를 수정해줍니다.
- 현재 내가 가진 참조 카운트가 1보다 크다면(unique하지 않다면), 새로운 값 타입을 생성하여 반환해줍니다. (copy)
자신이 생성한 struct에 copy on write를 적용하려면 setter에서 isUniquelyReferencedNonObjC를 체크해서 copy혹은 mutate 하도록 처리하는 코드를 작성하면 copy-on-write 기법을 적용할 수 있게 되는 것입니다.